train_x, train_y, test_x = rd.DellaGattaGene(backend='torch').get_data()
GP(0)
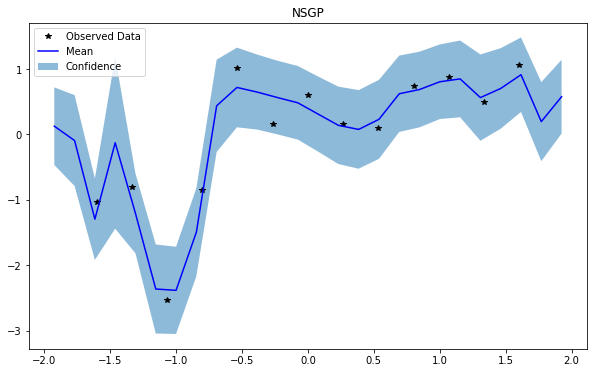
NSGP(num_latent=7)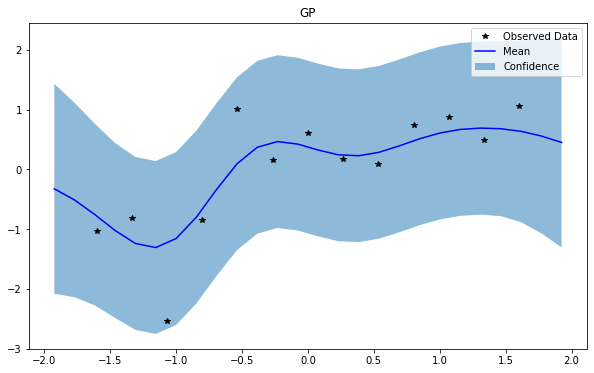
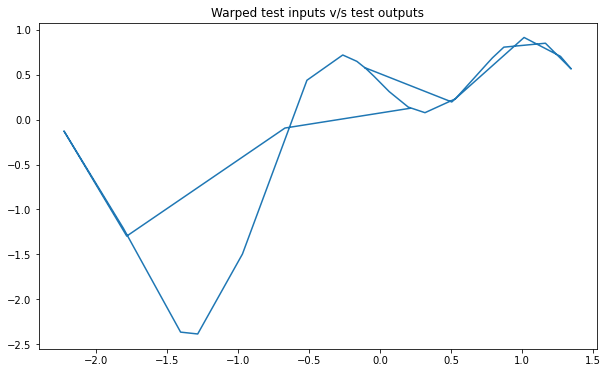
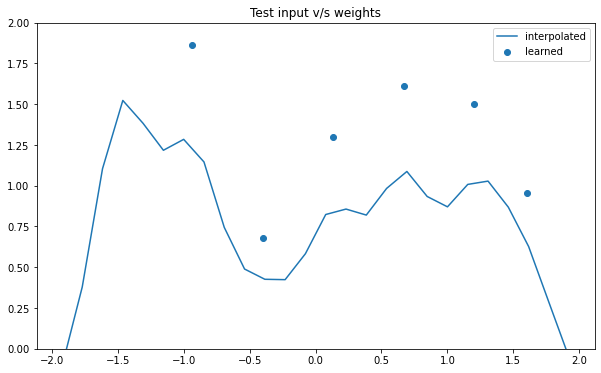
train_x, train_y, test_x = rd.DellaGattaGene(backend='torch').get_data()
GP(0)
NSGP(num_latent=7)
train_x, train_y, test_x = rd.Heinonen4(backend='torch').get_data()
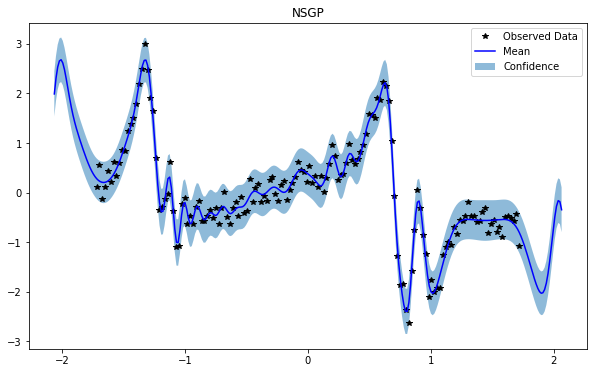
GP(0)
NSGP(num_latent=10)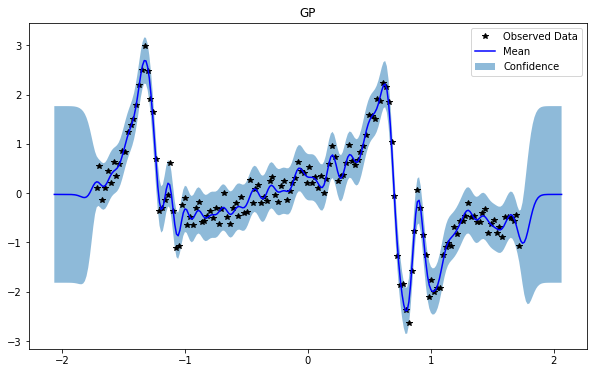
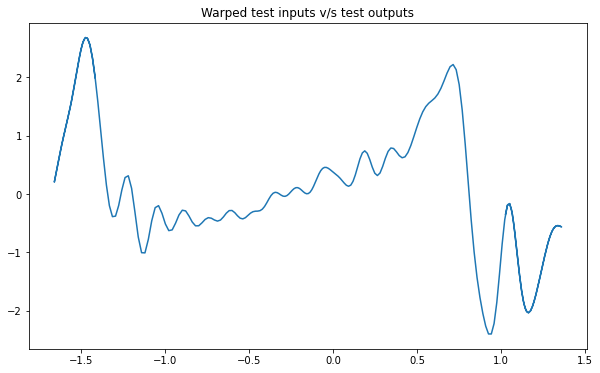
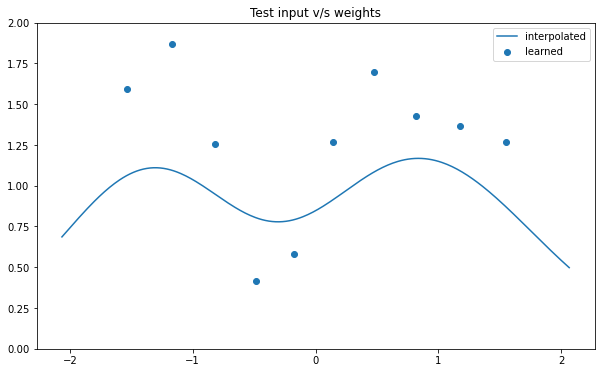
train_x, train_y, test_x = rd.Jump1D(backend='torch').get_data()
GP(0)
NSGP(num_latent=10)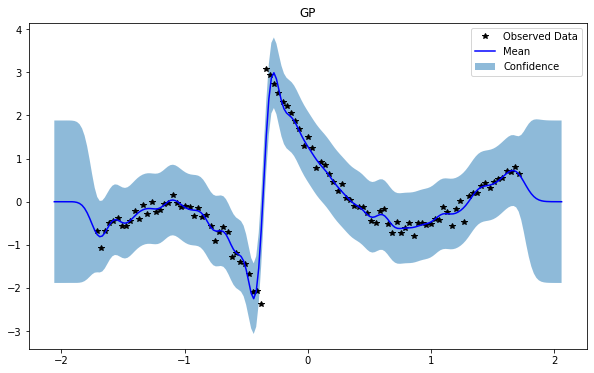
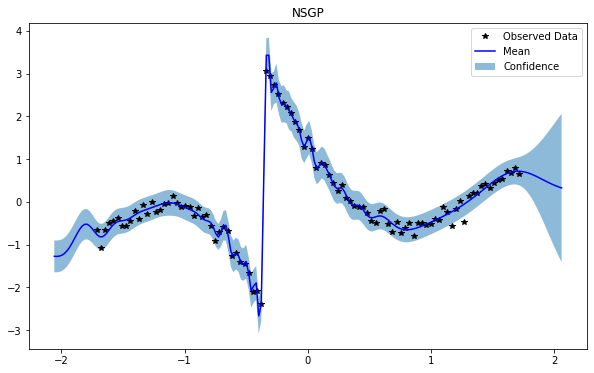
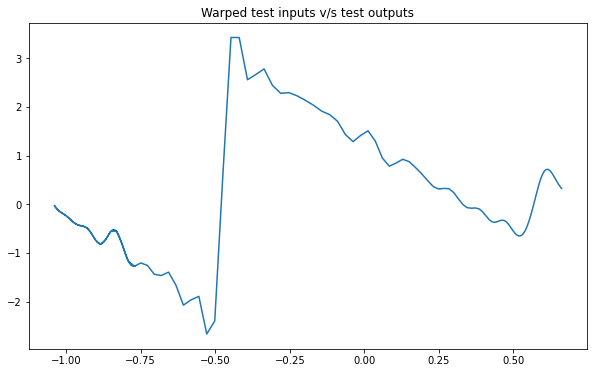
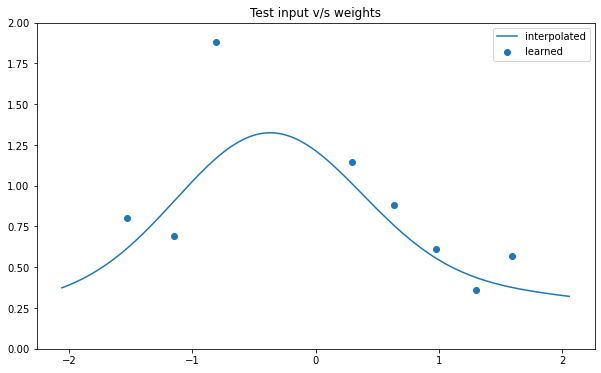
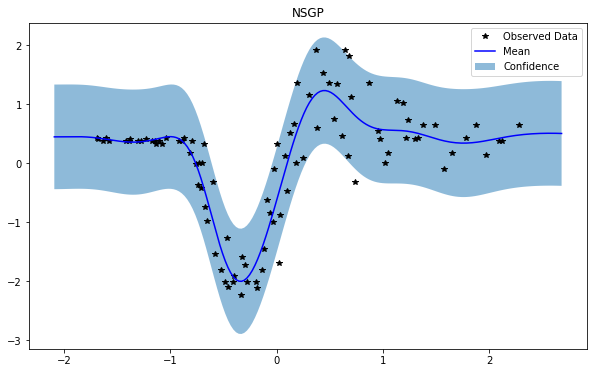
train_x, train_y, test_x = rd.MotorcycleHelmet(backend='torch').get_data()
GP(0)
NSGP(num_latent=10)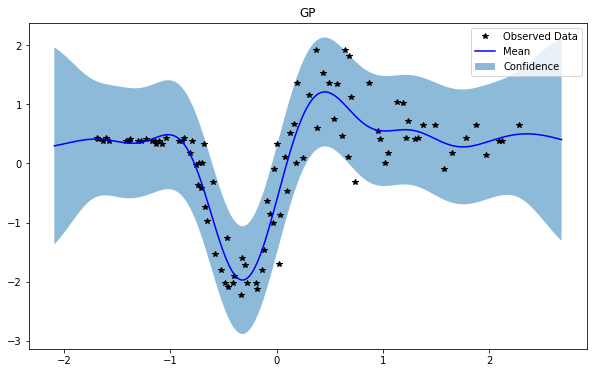
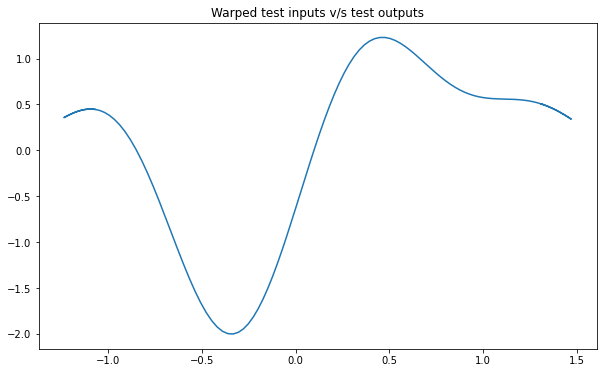
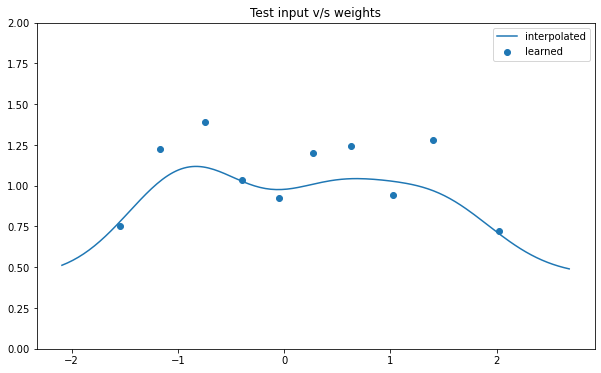
train_x, train_y, test_x = rd.Olympic(backend='torch').get_data()
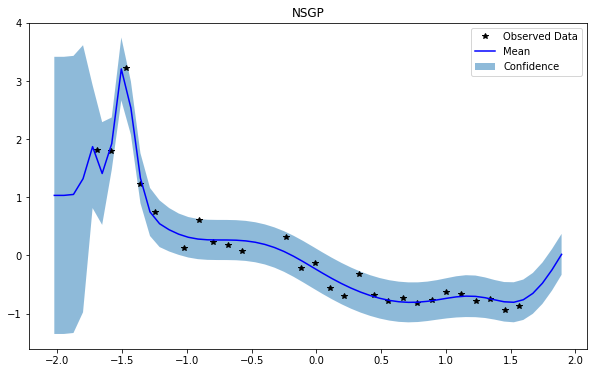
GP(0)
NSGP(num_latent=10)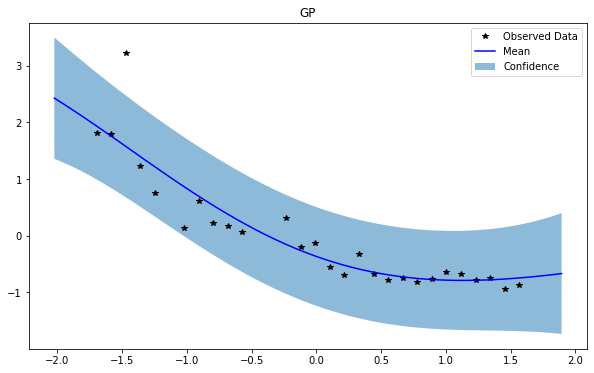
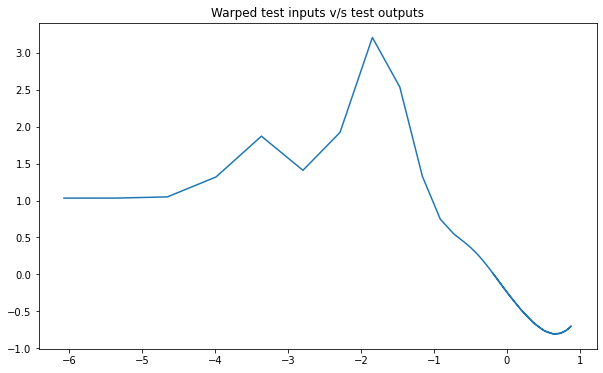
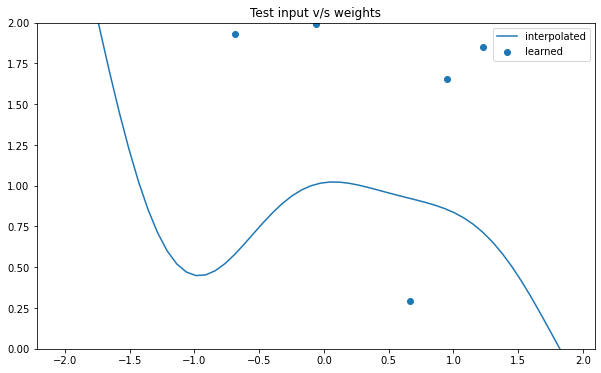
train_x, train_y, test_x = rd.SineJump1D(backend='torch').get_data()
GP(0)
NSGP(num_latent=10)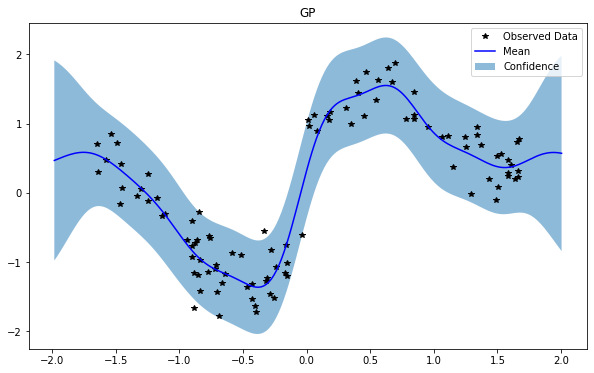
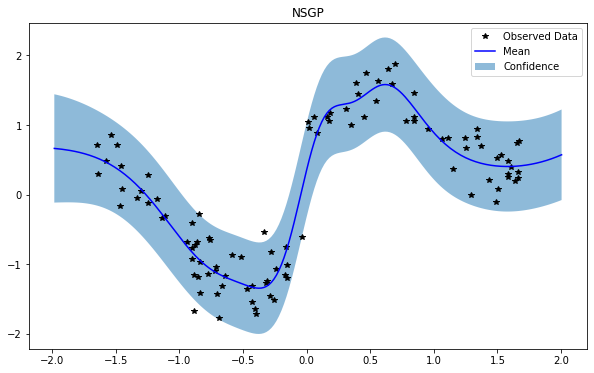
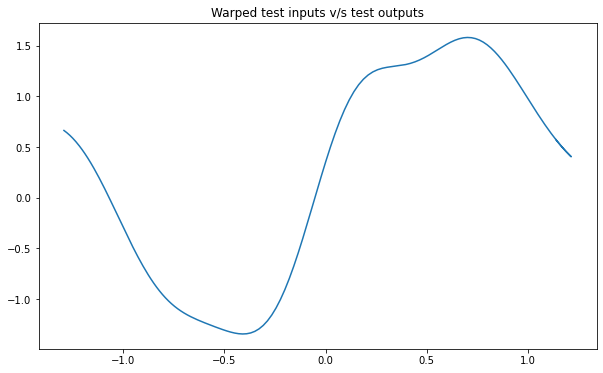
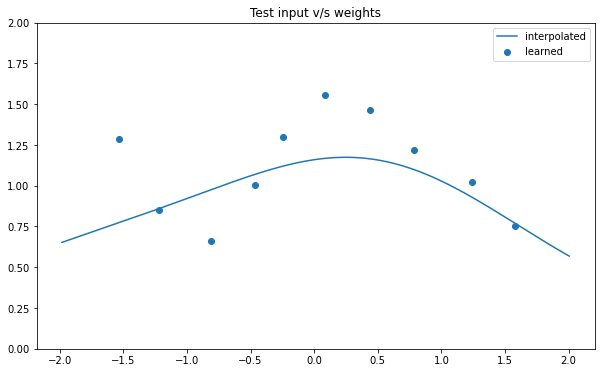
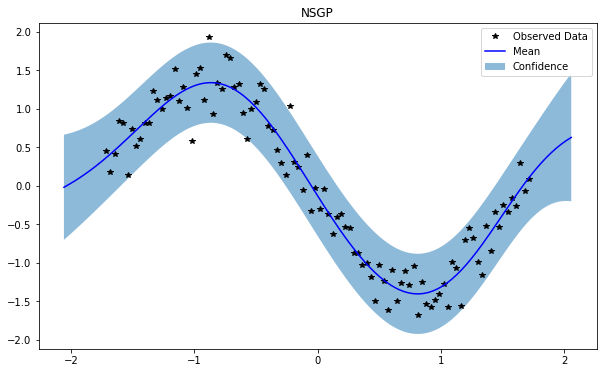
train_x, train_y, test_x = rd.SineNoisy(backend='torch').get_data()
GP(0)
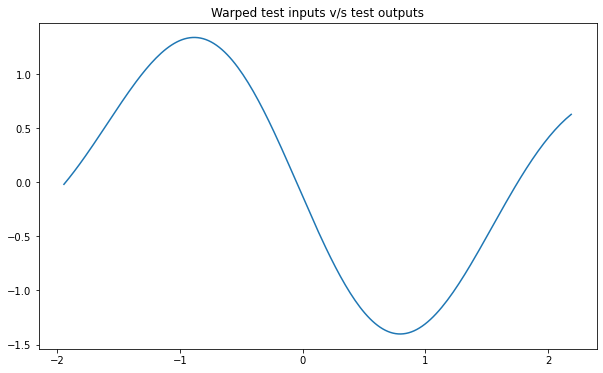
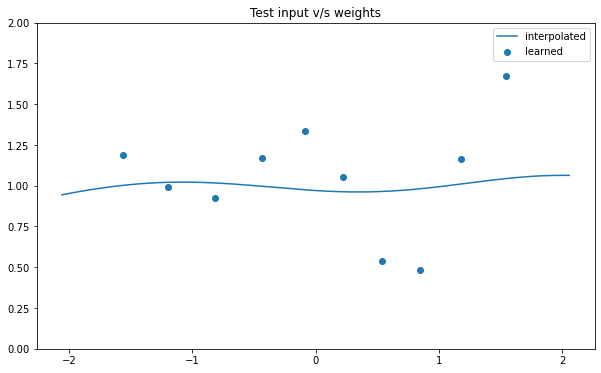
NSGP(num_latent=10)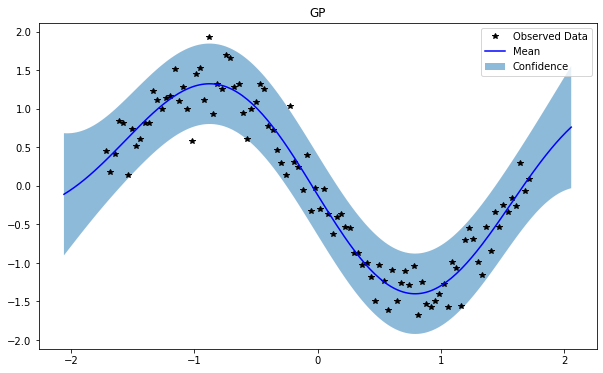
Comments