# Silence WARNING:root:The use of `check_types` is deprecated and does not have any effect.
# https://github.com/tensorflow/probability/issues/1523
import logging
logger = logging.getLogger()
class CheckTypesFilter(logging.Filter):
def filter(self, record):
return "check_types" not in record.getMessage()
logger.addFilter(CheckTypesFilter())
import jax
import jax.numpy as jnp
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
try:
import flax.linen as nn
except ModuleNotFoundError:
%pip install flax
import flax.linen as nn
try:
import optax
except ModuleNotFoundError:
%pip install optax
import optax
try:
import tensorflow_probability.substrates.jax as tfp
except ModuleNotFoundError:
%pip install tensorflow-probability
import tensorflow_probability.substrates.jax as tfp
tfd = tfp.distributionsModel
class Encoder(nn.Module):
features: list
encoding_dims: int
@nn.compact
def __call__(self, x_context, y_context):
x = jnp.hstack([x_context, y_context.reshape(x_context.shape[0], -1)])
for n_features in self.features:
x = nn.Dense(n_features)(x)
x = nn.relu(x)
x = nn.Dense(self.encoding_dims)(x)
representation = x.mean(axis=0, keepdims=True) # option 1
return representation # (1, encoding_dims)
class Decoder(nn.Module):
features: list
@nn.compact
def __call__(self, representation, x):
representation = jnp.repeat(representation, x.shape[0], axis=0)
x = jnp.hstack([representation, x])
for n_features in self.features:
x = nn.Dense(n_features)(x)
x = nn.relu(x)
x = nn.Dense(2)(x)
loc, raw_scale = x[:, 0], x[:, 1]
scale = jax.nn.softplus(raw_scale)
return loc, scale
class CNP(nn.Module):
encoder_features: list
encoding_dims: int
decoder_features: list
@nn.compact
def __call__(self, x_content, y_context, x_target):
representation = Encoder(self.encoder_features, self.encoding_dims)(x_content, y_context)
loc, scale = Decoder(self.decoder_features)(representation, x_target)
return loc, scale
def loss_fn(self, params, x_context, y_context, x_target, y_target):
loc, scale = self.apply(params, x_context, y_context, x_target)
predictive_distribution = tfd.MultivariateNormalDiag(loc=loc, scale_diag=scale)
return -predictive_distribution.log_prob(y_target)Data
N = 100
seed = jax.random.PRNGKey(0)
x = jnp.linspace(-1, 1, N).reshape(-1, 1)
f = lambda x: (jnp.sin(10*x) + x).flatten()
noise = jax.random.normal(seed, shape=(N,)) * 0.2
y = f(x) + noise
x_test = jnp.linspace(-2, 2, N*2+10).reshape(-1, 1)
y_test = f(x_test)
plt.scatter(x, y, label='train', zorder=5)
plt.scatter(x_test, y_test, label='test', alpha=0.5)
plt.legend();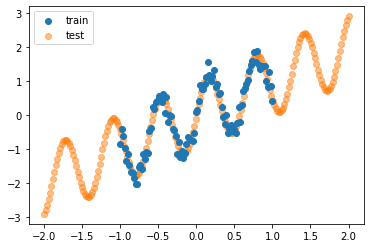
Training
def train_fn(model, optimizer, seed, n_iterations, n_context):
params = model.init(seed, x, y, x)
value_and_grad_fn = jax.value_and_grad(model.loss_fn)
state = optimizer.init(params)
indices = jnp.arange(N)
def one_step(params_and_state, seed):
params, state = params_and_state
shuffled_indices = jax.random.permutation(seed, indices)
context_indices = shuffled_indices[:n_context]
target_indices = shuffled_indices[n_context:]
x_context, y_context = x[context_indices], y[context_indices]
x_target, y_target = x[target_indices], y[target_indices]
loss, grads = value_and_grad_fn(params, x_context, y_context, x_target, y_target)
updates, state = optimizer.update(grads, state)
params = optax.apply_updates(params, updates)
return (params, state), loss
seeds = jax.random.split(seed, num=n_iterations)
(params, state), losses = jax.lax.scan(one_step, (params, state), seeds)
return params, lossesencoder_features = [64, 16, 8]
encoding_dims = 1
decoder_features = [16, 8]
model = CNP(encoder_features, encoding_dims, decoder_features)
optimizer = optax.adam(learning_rate=0.001)
seed = jax.random.PRNGKey(2)
n_context = int(0.7 * N)
n_iterations = 20000
params, losses = train_fn(model, optimizer, seed, n_iterations=n_iterations, n_context=n_context)plt.plot(losses);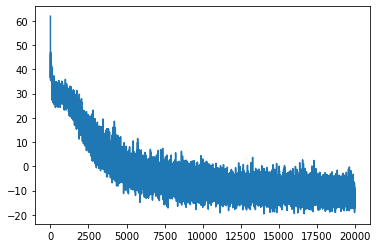
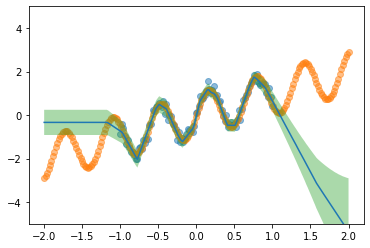
Predict
loc, scale = model.apply(params, x, y, x_test)
lower, upper = loc - 2*scale, loc + 2*scale
plt.scatter(x, y, label='train', alpha=0.5)
plt.scatter(x_test, y_test, label='test', alpha=0.5)
plt.plot(x_test, loc);
plt.fill_between(x_test.flatten(), lower, upper, alpha=0.4);
plt.ylim(-5, 5);