<frozen importlib._bootstrap>:228: RuntimeWarning: scipy._lib.messagestream.MessageStream size changed, may indicate binary incompatibility. Expected 56 from C header, got 64 from PyObject
Train a model on MNIST
# Define data transformationstransform = transforms.Compose( [ transforms.Resize((224, 224)), transforms.Grayscale(num_output_channels=3), # Convert to RGB format transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,)),# convert dtype to float32# transforms.Lambda(lambda x: x.to(torch.float32)), ])
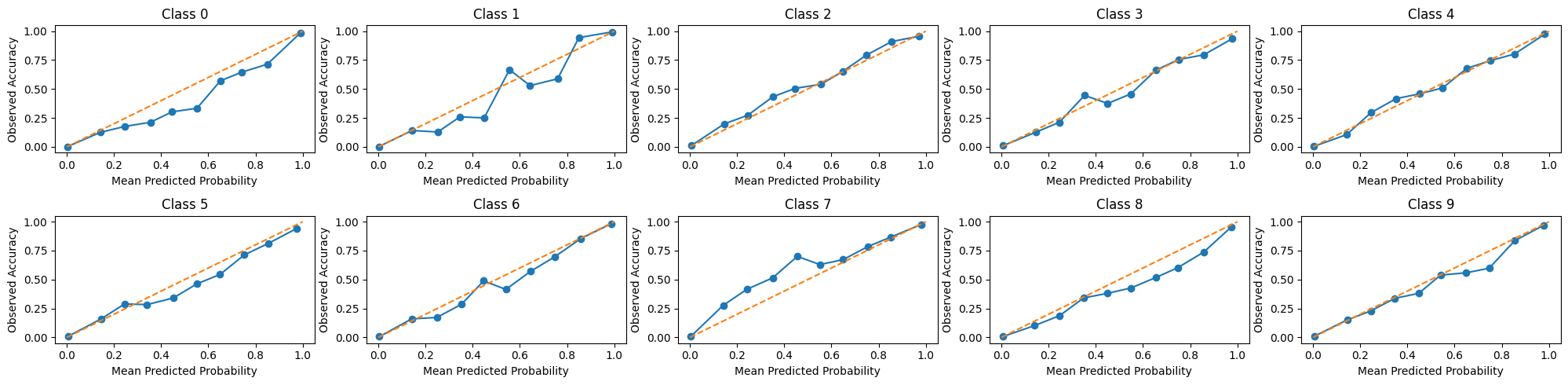
# Load pre-trained ResNet modelresnet = torchvision.models.resnet18(pretrained=True)print("Loaded pre-trained ResNet18 model")print(resnet.fc.in_features)# Modify the last fully connected layer to match MNIST's number of classes (10)num_classes =10resnet.fc = nn.Sequential( nn.Linear(resnet.fc.in_features, resnet.fc.in_features), nn.GELU(), nn.Linear(resnet.fc.in_features, num_classes),)# Freeze all layers except the last fully connected layerfor name, param in resnet.named_parameters(): param.requires_grad =Falseresnet.fc.requires_grad_(True)# Define loss and optimizercriterion = nn.CrossEntropyLoss()optimizer = torch.optim.Adam(resnet.parameters(), lr=1e-4)# Training loopnum_epochs =50print(f"Training on device {device}")resnet.to(device)print("Training ResNet18 model")for epoch inrange(num_epochs): resnet.train() epoch_loss =0.0for images, labels in tqdm(train_loader): optimizer.zero_grad() outputs = resnet(images) loss = criterion(outputs, labels) loss.backward() optimizer.step() epoch_loss += loss.item() epoch_loss /=len(train_loader)print(f"Epoch [{epoch+1}/{num_epochs}] Loss: {epoch_loss:.4f}")# Evaluation resnet.eval() correct =0 total =0with torch.no_grad(): predicted_list = []for images, labels in test_loader: outputs = resnet(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item()print(f"Accuracy on the test set: {(100* correct / total):.2f}%")
/home/patel_zeel/miniconda3/envs/torch_dt/lib/python3.9/site-packages/torchvision/models/_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
warnings.warn(
/home/patel_zeel/miniconda3/envs/torch_dt/lib/python3.9/site-packages/torchvision/models/_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=ResNet18_Weights.IMAGENET1K_V1`. You can also use `weights=ResNet18_Weights.DEFAULT` to get the most up-to-date weights.
warnings.warn(msg)
Loaded pre-trained ResNet18 model
512
Training on device cuda
Training ResNet18 model